
网络舆情监测的技术手段
网络舆情监测靠什么完成的?很多人应该不明白,也相知道这背后的原理,但是这背后的原理说难懂也不难,但是也不简单!那么下面就toom舆情的小编一起来看一下吧!
首先舆情监测第一步就是数据的获取,也就是我们常说的一些微博,微信等平台的信息的抓取,那么我们应该如何进行抓取?下面大致说一下!(因为涉及一些算法,太深了也不好懂!0.0)
说到这个抓取一般也就是有以下两种,一类是搜索引擎搜索,一种是就网站站内搜索。
这两种各有各的优势,我们做的舆情监测往往是有要监测的关键词的,那么在有了关键词也就是有了我们的监测主题,我们可以利用这些关键词去让程序去各种的搜索入口进行数据的爬取工作!(有人说爬虫不会累吗?!!!它不累!)
那么网站是不是会不认我们抓取?对的,是有这种情况的,我们的爬虫一直在网站抓取会对网站造成高负载,所以些站长的网站是有反爬虫机制的,他们的主要反爬方式就是输入验证码来核实是否是人工作为。不过我们也有应对的办法,这里就不多说了!感兴趣自行百度!
说完了站内爬虫,下面我们来说一下,搜索入口,相对来说搜索入口是比较方便的,除了爬取门槛低之外,不需要自己手动的收录网站信息,还有一个就是爬取的结果是跟人工一样准确的!
爬虫根据网站入口遍历爬取网站内容
第一步要规划好待爬取的网站有哪些? 根据不同的业务场景梳理不同的网站列表, 例如主题中谈到的只要监测热门的话题,这部分最容易的就是找门户类、热门类网站,爬取他们的首页推荐,做文章的聚合
这样就知道哪类是最热门的了。思路很简单,大家都关注的就是热门。至于内容网站怎么判断热门,这个是可以有反馈机制的:一类是编辑推荐;一类是用户行为点击收集,然后反馈排序到首页。
其次就是爬虫的获取数据,爬虫怎么写这个就不多逼逼(人生苦短,我用python)皮一下很开心,爬虫这个工作的入门确实不难但是他难在后期的提升!爬虫在提升,网站的反爬也在提升!唉,说多了!

数据抓取到以后应该怎么办?
数据获取以后那些是你需要的?那些是不用的?这个就用到了一些算法的处理!这个方面的门槛比较高,难度大,首先大规首先大规模的数据如何被有效的检索使用就是个难题。
比如一天收录一百万个页面(真实环境往往比这个数量级高很多),上百G的数据如何存储、如何检索都是难题。值得高兴的是业内已经有一些成熟的方案,比如使用solr或者es来做存储检索, 但随着数据量的增多、增大,这些也会面临着各种问题。
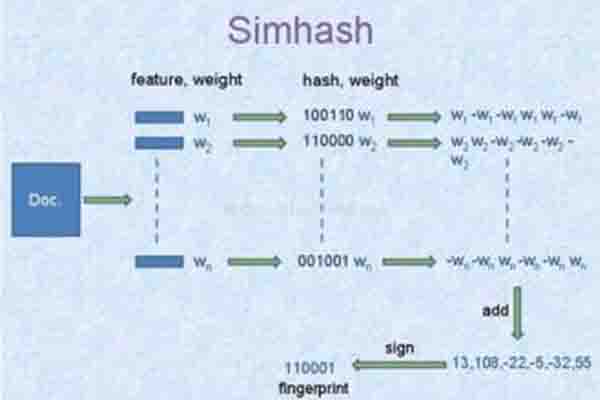
通常对热门的判断逻辑是被各家网站转载、报道的多, 所以使用NLP的手段来做相似性计算是必须的,业内常用的方法有Simhash或者计算相似性余弦夹角。有些场景不单单是文章相似,还需要把类似谈及的文章都做聚合,这时就需要用到一些聚类算法,例如LDA算法。从实践经验来看,聚类算法的效果良莠不齐, 需要根据文本特征的情况来测试。
目前舆情监测的现状存在很多待改进的地方。首先,手工监测存在天然局限性。通过安排固定人手24小时值班,不间断地浏览目标站点并搜索目标关键词,是在缺少自动化系统时最直接也是最初级的舆情监测方式。
由于受到每个人主观思想的限制,手工监测总会有观察盲区,总会有觉得不重要但事后被证明很严重的地方,且手工无法察觉到一些站点或者一些偏僻的网页内容发生改变;同时
人不是机器,长期反复监测容易导致疲劳,经常会使得该判断出来的舆情,一不留神就漏掉了。这些都会在实时性和准确性上存在很大波动。
以上这也就是舆情监测的用到的一些技术手段,还是有一些专业知识的,不懂也没事不慌,我们可以百度一下,一点点的分析出来!以上就是小编今天为你带来的文章,如果你还有什么不懂的也可以来电咨询哦!
版权声明: TOOM舆情监测软件平台,致力于为客户提供从全网信息监控到危机事件应对和品牌宣传推广的一整套解决方案,拥有多个服务器机房中心和专业的舆情分析师团队。 本文由【TOOM】原创,转载请保留链接: https://www.toom.cn/news/2296.html ,部分文章内容来源网络,如有侵权请联系我们删除处理。谢谢!!!
相关文章
-
网络舆情监测的技术手段
网络舆情监测靠什么完成的?很多人应该不明白,也相知道这背后的原理,但是这背后的原理说难懂也不难,但是也不简单!那么下面就toom舆情的小编一起来看一下吧! 首先舆情监测第一
2019-03-18 14:21:31
- 联系我们
- 010-80700019
- 186-1817-7820
- 1169226953
- zhangliang@toom.cn
- 北京市昌平区沙河青年创业大厦A座
- 权威认证
- CSA STAR Certification国际认证
- ISO27001信息安全管理体系国际认证
- 关注我们


